




京卫计网审[2015]第0523号 京ICP备14051922号 京ICP证160408号
京公网安备 11010502030806号 Copyright © 2014 北京易康医疗科技有限公司版权
全国免费咨询热线
400-627-0012
发布时间:2016-06-17 | 来源: | 责任编辑:嗵嗵e研
当绘制柱状图的时候,您是不是曾经遇到这样的困惑。用柱状图表述一组均值,在绘制柱顶端的范围时,到底应该用标准差、标准误还是可信区间,或者是参考值范围?要想解答这一问题,应该首先问问自己,我们到底是想探讨一次抽样的均值可能是什么,还是想探讨一次抽样的每个个体的值大致落在什么范围。
这就是在描述的时候,样本群体和每个样本个体的差异。让我们先放下这个执念,复习一下统计学的两个基本知识——标准差和标准误。简单来说,标准差是反映一个总体内,个体间的离散程度的指标,即每个个体都会在距离总体真实均值的某一个标准差范围内波动;标准误则是衡量一个总体被抽出样本的均值,距离总体均值的真实水平的差距可能有多少,标准误不仅受总体内每个个体变异水平的影响,还受抽样的样本量大小影响,是反应抽样的均值波动范围的指标。
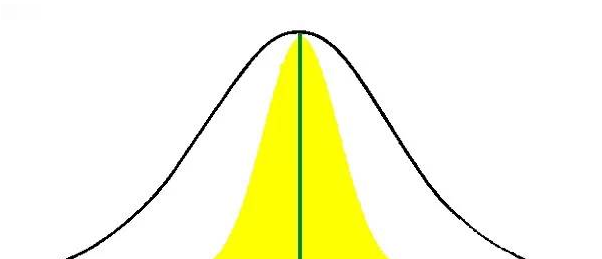
是不是还是太晦涩了?让我们看个例子吧。假设我们在某个人群总体中抽了10个样本,并计算得到了一个均值(上图中间的绿线)。那么由此可以估计出,总体中每个个体的分布如外面的黑线区域所示。同时,如果我们对这个总体反复多次进行重复抽样,每次都抽取10个人,那么经过多次抽样并计算均值后,我们会发现均值都落在了黄色的区域。黑线框住的部分就是个体的分布范围;黄色的区域就是样本量为10时,抽样均值的波动范围。
现在可以往下说了,在我们针对一个样本计算得到一个均值之后,我们期望告诉大家的是样本背后的总体的真实均值是多少。正由于我们得到的均值是通过抽样获得的,因此其不仅不一定等于均值,而且每次抽样的均值也不一定相同。因此我们在给出均值的时候,就要同时告诉大家这样抽样的话,均值会在什么范围内波动,这就是均值的“可信区间”。由此不难看出,均值的可信区间是与上述黄色区域对应的。从公式上说,均值的可信区间可以通过均值和标准误计算得到(95%可信区间为均值±1.96标准误),前提是确定可信范围(80%、90%还是95%)。
而统计学角度的参考值范围,则是群体内每个个体的取值水平。对应的是上图的黑线下方的全部区域。故统计学角度的参考值范围是同均值和标准差计算得到的(95%参考值范围是均值±1.96标准差)。
当然提到参考值范围的时候,我们不能仅考虑如何计算。因为医学的参考值制定本身还有一整套体系。由于参考值多用于界定某个值是否处于正常或异常水平,因此参考值范围的确定过程更多要考虑到临床的实际意义,参考范围松紧也要参考实际临床需求。
回到开头的问题,我想已经不需要我多做解释了。当您期望描述一个抽样中每个个体的分布时,就用标准差、参考值范围;而要想描述此次抽样均值的波动范围的话,就应该用标准误和均值的可信区间了。

京卫计网审[2015]第0523号 京ICP备14051922号 京ICP证160408号
京公网安备 11010502030806号 Copyright © 2014 北京易康医疗科技有限公司版权