




京卫计网审[2015]第0523号 京ICP备14051922号 京ICP证160408号
京公网安备 11010502030806号 Copyright © 2014 北京易康医疗科技有限公司版权
全国免费咨询热线
400-627-0012
发布时间:2016-06-16 | 来源: | 责任编辑:嗵嗵e研

倾向评分的基本理论用一句话概括倾向评分就是用一个方程模型将全部混杂变量综合成一个混杂变量,即倾向评分(propensity score,以下简称PS),再通过调整倾向评分使两组间的混杂因素达到平衡,实现“随机”的效果。多用于非随机的临床试验及随机化失败的临床试验。今天我们主要看看倾向评分怎么估算。
倾向评分的估计是通过将处理因素作为应变量,其它混杂因素作为自变量建立可以计算概率的模型来估计,也就是要构建一个倾向评分模型。最常用的模型为Logistic回归和判别分析,也有人尝试使用Probit回归、非参数回归、半参数回归等。由于判别分析要求协变量服从多元正态分布,而Logistic回归对数据分布没有要求,因此建立模型时Logistic回归最为常用。
用Logistic回归建立模型即是处理因素(即分组)作为应变量,其它混杂因素作为自变量进行回归的过程。需要注意的是评分模型中应该包括所有与研究结局有关的变量。得到方程模型:
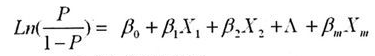
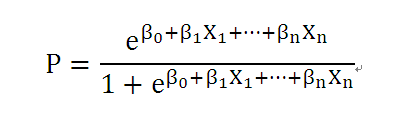
上述得到的P即为倾向评分,取值在[0,1]范围内。根据上述公式,可以计算出每个个体的倾向评分。
得到倾向评分模型后,需要对模型的拟合优度进行判断。常用的方法为Hosmer-Lemeshow检验和ROC曲线下的面积(C值),前者会在Logistic回归结果中给出,当其P<0.05,认为模型成立。后者需要再用分组变量(处理因素)与倾向评分作ROC曲线,有文献认为C值>=0.8模型拟合较好,但如果C值太高,则处理组和对照组倾向评分有效重叠的范围(共同支持范围)将非常小,这种情况下两组的可比性将非常差。
估算出倾向评分之后,即相当于将多个混杂因素综合成一个混杂变量,如果调整倾向评分使两组间混杂因素平衡呢?现在常用的调整方法有四种,即回归调整, 分层, 加权标化和配比。
倾向评分回归调整即将倾向评分作为一个混杂因素与处理因素(分组)一起作为自变量,以研究的结局为因变量,进行多因素回归分析。在此不多赘述。
倾向评分分层是指按照倾向评分将全部观察对象分为5-10层,由于每层内倾向评分相差不大,认为每层内混杂因素也是平衡的,依次分析每层内各个观察结果变量(因变量)和处理变量及分层变量的关系,再合并分析。
倾向评分加权标化是指根据每个个体的评分给每个个体一个权重,加权后进行统计分析。常用的加权方法有逆处理概率加权法(inverse probabilityof treatment weighting,IPTW)和标准化死亡比加权法(standardized mortality ratio weighting,SMRW)。逆处理概率加权法是Robins等人给出的,Heman等在Robins给出的公式基础上对计算方法进行调整。具体方法是:处理组观察单位的权数Wt=Pt/PS,对照组观察单位的权数Wc=(1-Pt)/(1-PS)。(Pt为整个人群中接受处理因素的比例,Pt=试验组个体数/两组总个体总数; PS为倾向评分。)
倾向评分配比是利用倾向评分从对照组中为处理组每个个体寻找1个或多个背景特征相同或相似的个体作为对照,最终两组的混杂变量也趋于均衡可比。通常用于对照组个体数较多的试验,在配比时可以一个试验组个体配比1到4个对照。最邻配比法是比较常用的配比方法。操作方法是:首先估算倾向评分,其次设计一个配比精度和配比比例,如配比精度为<0.01,配比比例为1:1.从试验组中拿出第一个个体,在对照组中选择与其倾向评分相差小于0.01的个体.如果评分相差小于0.01只有一个个体,配比成功;如果有多个个体,随机从几个中抽取一个作为对照。再进行试验组第二个个体的配比……配比完成后进行统计分析。

京卫计网审[2015]第0523号 京ICP备14051922号 京ICP证160408号
京公网安备 11010502030806号 Copyright © 2014 北京易康医疗科技有限公司版权