




京卫计网审[2015]第0523号 京ICP备14051922号 京ICP证160408号
京公网安备 11010502030806号 Copyright © 2014 北京易康医疗科技有限公司版权
全国免费咨询热线
400-627-0012
发布时间:2016-06-01 | 来源: | 责任编辑:嗵嗵e研

通过第一阶段的选题和立题学习,大家脑海里应该有了一定的想法,有了好的选题之后,那么你就有了一个初步的概念,接下来嗵嗵就把工作量最大的第二阶段发给大家,这个阶段也是需要接触到各种工具和大量知识储备的时候,所以大家需要了解各种文献检索工具,需要熟练运用相关统计软件,这些工作都是要有一定的基础来支撑,那么第二阶段的重要性就可想而知。
第一步:文献检索
在制定文献检索策略时,总体的要求就是查全和查准。
需要考虑如下几个方面:
1. 圈定搜索数据库(外文有:MEDLINE、the Cochrane library、医学文摘、TOXLINE、OVID、EMBASE、ISI Web of Science、EBSCO等;国内有:维普全文VIP、CNKI、万方数据库)
2. 确定语言类型:包括所有英语和非英语的文献;
3. 明确需要包含的研究类型:仅包含RCT,还是病例对照试验,队列研究等。
4. 明确暴露因素/治疗方法
5. 筛选关键词:这将直接影响文献检索的准确性和敏感性,也关系到指定检索策略。
- 关键词需要根据研究问题本身来确定;
- 对于每一个关键词尽量包含所有可能的表述形式;
- 可以尝试几种关键词组合以搜最合适的文献。
6. 检索获取摘要和全文:其中联系专家是一种很好的方式,不仅可以获取全文,甚至可以询问文献中的细节帮助后续使用文献。建议搜索文献引用名单,可以增加文献搜索的全面性。
在例文中,作者搜索了所有英语和非英语的文章,包括:
Medline、Cochrane对照试验注册、Embase、专家、搜索文献引用名单、在美国骨骼和矿物质研究协会中的摘要。在搜索的过程中,主要使用的医学关键词包括“vitamin D” OR “vitD”, “falls” OR “accidental falls”、“human”等。第二步:根据纳入/排除标准完成文献选择
总体来说,首先在计划书中需要描述纳入/排除标准,且这些标准不应该是看了搜索的文献后制定的,而是应从评价问题出发直接得出。
在文献筛选过程中,首先,需要由两位研究者独立通过对文献的题目和摘要进行初筛,初筛后的文献通过阅读全文进行二次筛选,然后交叉核对筛选结果,如果有分歧则通过共同讨论决定是否纳入,必要时可有第三位研究者协助解决。如果文中信息不全或信息不清楚,与原始研究作者联系获取信息。在筛选过程中,需要记录你每个步骤的选择和排除原因。至于被排除的文章,则需要在灵敏度分析中进行分析。
如例文,在这个文献中,已提前确定了纳入和排除标准,包括:仅包含RCT研究,参加人群平均年龄≥60岁,排除酗酒人群、健康不稳定人群等,而所排除的研究在灵敏度分析中进行了分析。
下面的这个流程表描述了整个meta分析纳入和排除的过程,这个流程表在meta分析中一般都是必要的。
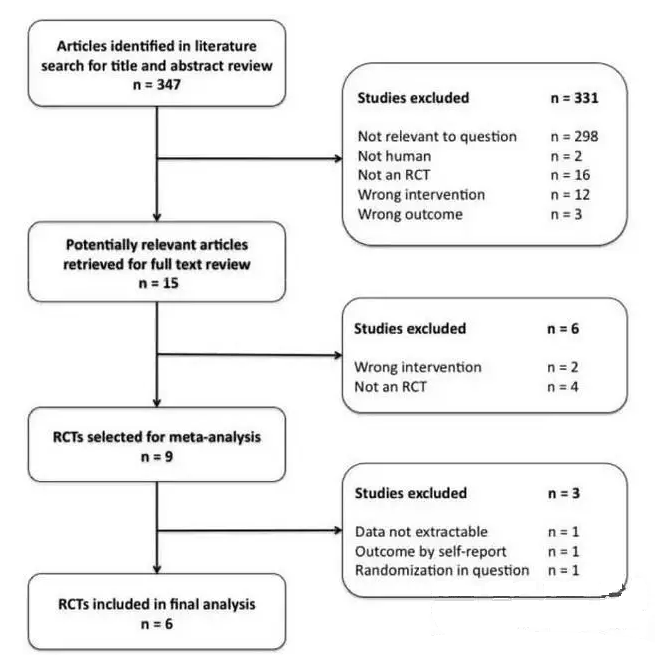
第三步:资料选择和提取
资料提取是从符合纳入要求的文献中摘录用于系统评价的数据信息,所提取信息必须是可靠、有效、无偏的。
总体来说,在进行数据提取时必须使用数据提取表对每个研究进行数据提取,时刻记住所评价的问题以及以后的分析。有时可能需要主观决定提取的信息,所以必须由2人独立进行,核查过程中遇到不同之处应该通过讨论解决。对于无法获取必要信息的文献,则应予以排除。
从提取的数据角度,需要提取相关研究的特点、结果和质量数据。
拿例文说,就有如下图对目标文章所提取的数据进行了总结:
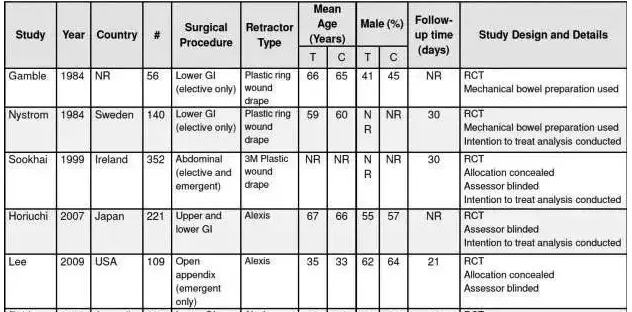
第四步:纳入研究的质量评价和特征描述
完成数据提取后,就需要对所选择的文献进行质量评估。常常通过评价一个研究在设计、实施和分析中防止和减少系统误差(偏倚)和随机误差的程度,来评价其研究质量,并以此为依据在敏感性分析、亚组分析中给以不同的权重。
评估的角度有很多,常需要包含以下领域条目:
· 研究设计是否与研究目的相匹配
· 偏倚风险
· 结果选择
· 统计问题
· 报告方式
· 干预/暴露测量
下面,陈列一下常用的文献质量评价工具:
1. 随机对照试验的质量评价工具:
Cochrane风险偏倚评估工具(最常用)、PEDro量表、Delphi清单、CASP清单、Jadad量表、Chalmers量表、CONSORT声明(不专用,但可以用)。
2. 观察性研究的质量评价工具:
(1)NOS量表(最常用):病例对照研究和队列研究;
(2)CASP清单:病例对照研究和队列研究;
(3)JBI标准:横断面研究;经验总结、案例分析及专家意见;
(4)AHRQ;
(5)Combie横断面研究评价工具;
(6)STROBE声明;
(7)STREGA声明。
3. 非随机对照实验性研究的质量评价工具:
MINORS条目、Reisch评价工具、TREND声明。
4. 诊断性研究:
QUADAS工具、CASP清单、STARD声明。
5. 动物试验:
STAIR清单、CAMARADES清单、ARRIV指南。
在该例文中,共有三名作者独立进行数据提取,使用已经设计好的数据领域,包括研究质量指数,评估了以下方法:随机方法、随机分配、双盲等。此外,还做了灵敏度分析。
第五步:数据整合
系统评价过程中,对上述数据进行定量统计合并的流行病学方法称为Meta分析(Meta analysis)。Meta意思是more comprehensive,即更加全面综合。对数据的整合分为描述性整合和定量整合:
对于描述性整合,应考虑:
• 建立干预/暴露因素是如何导致结果的假说,包括原因和适用人群;
• 初步综合纳入的研究,以文本形式或者制表和/或图形显示;
• 探讨各研究内或各研究间的关系;
• 评估证据的稳定性;
• 评估meta分析的重要性。
对于定量整合,则可以:
1. 提高了统计检验的power和精度;
2. 统计结合各研究结果给出一个“平均”干预效果的合并估计值,改进对作用效应的估计;
3. 评价结果一致性,解决单个研究间的矛盾;
4. 解决以往单个研究未明确的新问题。
那么如何进行meta分析呢?
a.异质性检验(齐性检验)
由于纳入文献存在临床异质性、方法学异质性和统计学异质性,所以在对结果数据进行统计合并之前,首先应该进行异质性检验,保证现有的各独立研究间的结果的不同仅仅是由于抽样误差造成的。否则,就要进入亚组分析,或取消合并。
异质性评估(Heterogeneity assessment)
• 异质性:除抽样误差外的不同性
• Chi-square test for interaction (Q = x2 statistic, df =degrees of freedom)
• 也可以比较各亚组的点估计是否相同
• 若同时如何I2<50%和P≥0.1时,纳入文献被认为是同质的,采用固定效应模型(fixed effect model)分析;反之说明研究间存在实际异质性,需要查找一致性的来源,之后采用随机效应模型(random effect model)。
• 如果存在较大的临床异质性,那将无法进行meta分析,只能进行描述性整合。
在JAMA这篇文章中,用Q值来评估异质性。当p值小于0.1时,存在显著异质性。此外,在forest plots中所有研究的95%置信区间相互之间重叠可支持不存在异质性。
b.统计合并效应量(加权合并,计算效应尺度及95%的置信区间)并进行统计推断
通常在考虑采用哪些效应指标(effect size)时需要考虑结局指标的类型,通常两组间比较时,如果是连续性变量用加权均数差(weighted mean difference, WMD)、标准化均数差值(standardized mean differences, SMD)表示效应大小;二分类变量则用率差(rate difference, RD)、比数比(odds ratio, OR)、相对危险度(relative risk, RR)、相对危险度降低值(relative risk reduction, RRR)等来表示效应的大小。
c.图示单个试验的结果和合并后的结果
-森林图(Forrest plot)
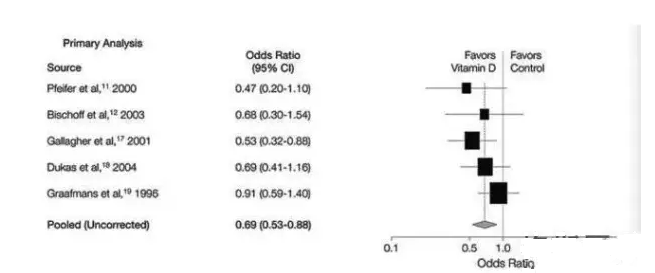
分别展示了纳入的每一篇文献的结果和合并后的结果。
-Meta-regression (Goodman et al, 2009)

d.敏感性分析:用来评估meta分析结果的稳定性
1)按研究质量评价标准从纳入文献中去除尚有争议的研究、排除低质量的研究、早期研究、根据研究结果的分布去掉extreme10%其他已知因素不同的研究;
2)采用不同统计方法/模型;
3)根据样本量大小进行分层分析;
4)改变纳入/排除标准时,重新对同一资料进行分析时,如果观察到合并指标点估计和区间估计的变化存在较大差异,则说明meta分析的结果不稳定。比如,当排除一篇低质量文献时,合并指标变化很大,说明该文献对合并指标敏感。
敏感性分析是必要的,无论是采用不同的统计模型或进行亚组分析,都可以帮助我们找到可能的偏倚来源,更加正确的理解获得的结论。
e.通过“失安全数”的计算或采用“倒漏斗图”对入选文献进行潜在的发表偏倚(publication bias)的评估。
可以用stata软件进行Begg test和 Egger test以及funnel plot进行评估。

京卫计网审[2015]第0523号 京ICP备14051922号 京ICP证160408号
京公网安备 11010502030806号 Copyright © 2014 北京易康医疗科技有限公司版权